[AI SCHOOL 5기] 데이터 분석 실습 - 데이터 탐색
Visualization Library #
python
import seaborn as sns
sns.heatmap(gu_df[])
Visualization Issues #
- 한글 데이터 표시 오류
- 서로 다른 자릿수로 구성된 열에 동일한 스케일 적용
- 시각화된 테이블 형태의 비직관성 문제
- 인구수가 고려되지 않은 부정확한 데이터
한글 데이터 시각화 #
python
matplotlib inline
# Windows
font_name = font_manager.FontProperties(fname="C:/~/malgun.ttf").get_name()
rc('font', family=font_name)
# Mac
rc('font', family='AppleGothic')Feature Scaling/Normalization #
- Min-Max Algorithm
- 열에 대한 최솟값(min)을 0, 열에 대한 최댓값(max)를 1로 맞춤
- 기존 열을 old_x, 새로운 열을 new_x라 할 때,
new_x = ( old_x - min(column) ) / ( max(column) - min(column) )
- Standardization
- 열에 대한 평균값(mean)을 0, 열에 대한 표준편차 값(std)를 1로 맞춤
- 기존 열을 old_x, 새로운 열을 new_x라 할 때,
new_x = ( old_x - mean(column) ) / std(column) - 표준 점수 (Z-score)와 동일
시각화 개선 #
- 전체 테이블의 사이즈 조정
pit.figure(figsize = (x, y)) - 셀 형식 및 색상 등 변경
sns.heatmap(norm, annot=, fmt=, linewidths=, cmap=)annot: 셀 내에 수치 입력 여부 (defualt False)fmt: 셀 내에 입력될 수치의 format ('f' == float)linewidths: 셀 간 거리 (내부 테두리)cmap: matplotlib colormap @https://goo.gl/YWpBES
- 테이블 제목 설정
plt.tile() - 시각화 설정된 테이블 표시
plt.show()
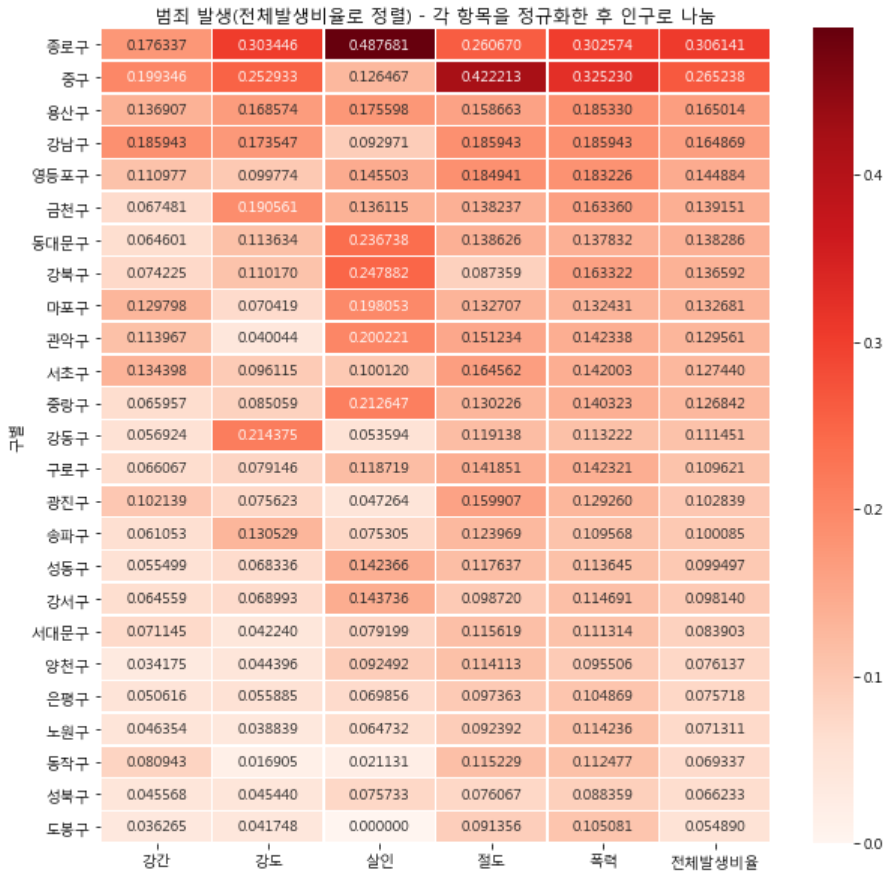
데이터 정확성 개선 #
- 범죄 발생 횟수에 인구수 반영
python
# 시각화된 데이터에서 열방향(axis=0)을 기준으로 인구수 데이터를 나눔 (인구 10만 단위)
crime_ratio = crime_count_norm.div(gu_df['인구수'], axis=0) * 100000- 구별 5대 범죄 발생 수치 평균 계산
python
crime_ratio['전체발생비율'] = crime_ratio.mean(axis=1)- 각 사건들의 중형도를 고려하지 못할 수 있음
- ‘살인’ 열에 스케일 적용 중 이미 큰 값이 곱해졌기 때문에 가중치가 적용되었다고도 판단 가능
Improved Visualization #
python
plt.figure(figsize = (10,10))
sns.heatmap(crime_ratio.sort_values(by='전체발생비율', ascending=False),
annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(전체발생비율로 정렬) - 각 항목을 정규화한 후 인구로 나눔')
plt.show()