[AI SCHOOL 5기] 텍스트 분석 실습 - 텍스트 분석
NLTK Library #
- NLTK(Natural Language Toolkit)은 자연어 처리를 위한 라이브러리
python
import nltk
nltk.download()문장을 단어 수준에서 토큰화 #
python
sentence = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
nltk.word_tokenize(sentence)Output
bash
['NLTK',
'is',
'a',
'leading',
'platform',
...POS Tagging #
python
tokens = nltk.word_tokenize(sentence)
nltk.pos_tag(tokens)Output
bash
[('NLTK', 'NNP'),
('is', 'VBZ'),
('a', 'DT'),
('leading', 'VBG'),
('platform', 'NN'),
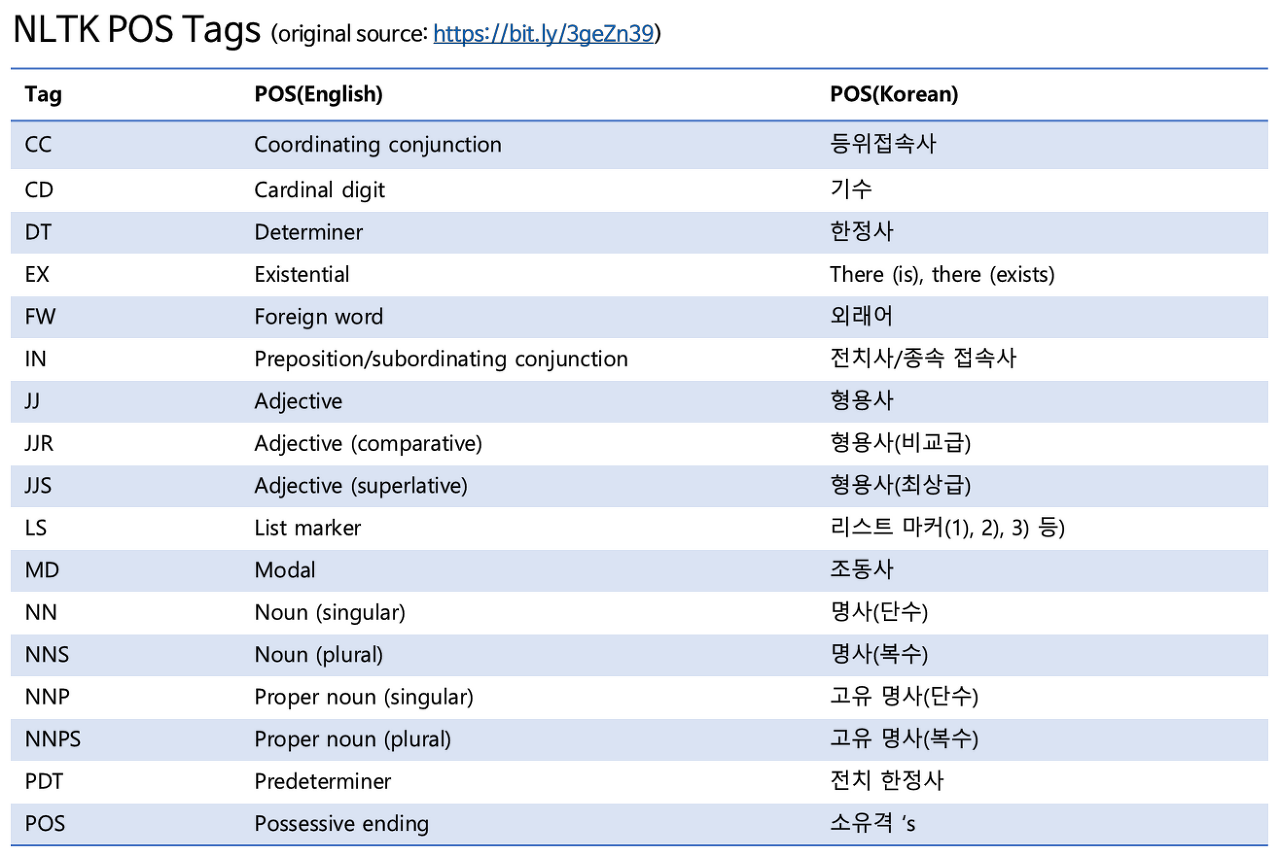
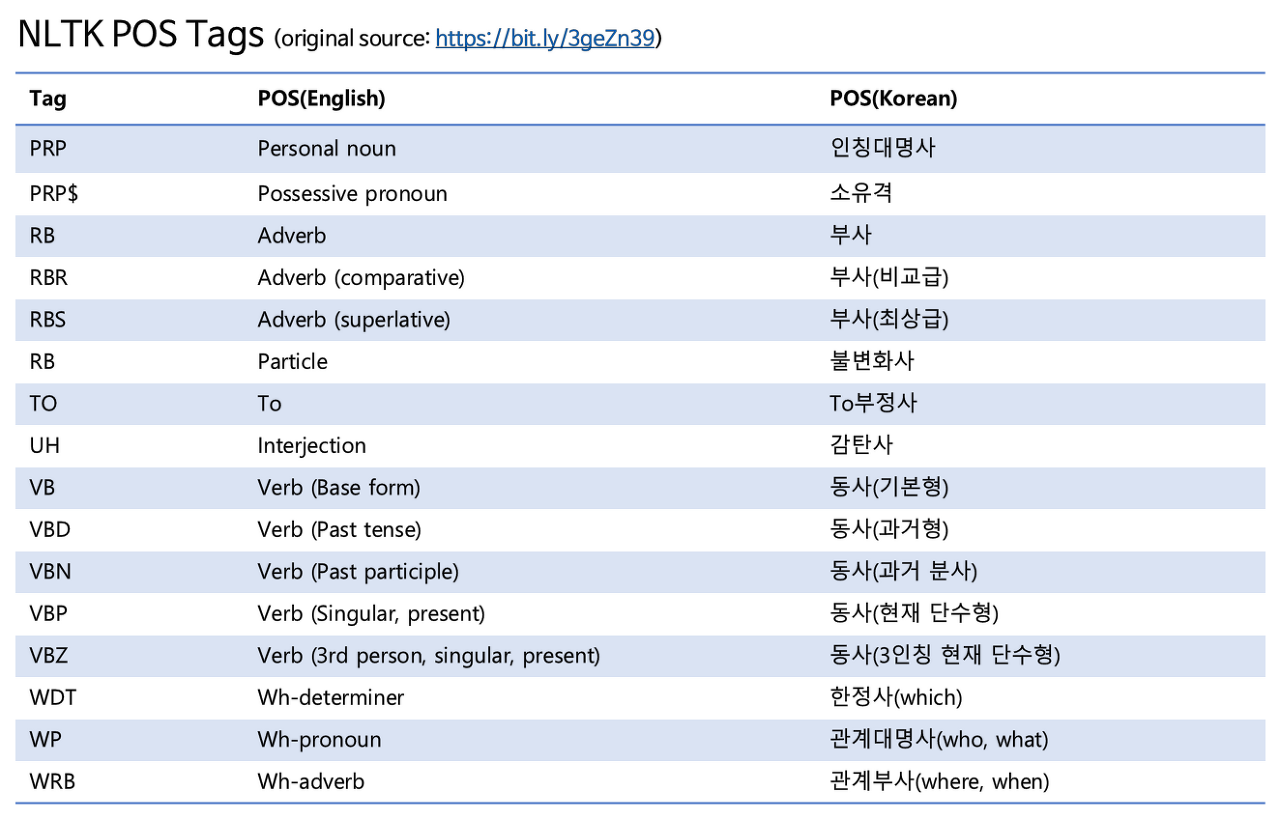
...NLTK POS Tags List #
Stopwords 제거 #
python
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.append(',')
stop_words.append('.')
result = []
for token in tokens:
if token.lower() not in stopWords:
result.append(token)Output
python
['NLTK', 'leading', 'platform', 'building', 'Python', 'programs', 'work', 'human', 'language', 'data', 'provides', 'easy-to-use', 'interfaces', '50', 'corpora', 'lexical', 'resources', 'WordNet', 'along', 'suite', 'text', 'processing', 'libraries', 'classification', 'tokenization', 'stemming', 'tagging', 'parsing', 'semantic', 'reasoning', 'wrappers', 'industrial-strength', 'NLP', 'libraries', 'active', 'discussion', 'forum']Lemmatizing #
- Lemmatization: 단어의 형태소적/사전적 분석을 통해 파생적 의미를 제거하고,
어근에 기반하여 기본 사전형인 lemma를 찾는 것
python
lemmatizer = nltk.wordnet.WordNetLemmatizer()
print(lemmatizer.lemmatize("cats")) # cat
print(lemmatizer.lemmatize("geese")) # goose
print(lemmatizer.lemmatize("better")) # better
print(lemmatizer.lemmatize("better", pos="a")) # good
print(lemmatizer.lemmatize("ran")) # ran
print(lemmatizer.lemmatize("ran", 'v')) # run- default로
n이므로 ‘cats’, ‘geese’ 들은 기본명사형을 반환 - 형용사 ‘better’는
pos에a를 함께 입력해주어야 원형인 ‘good’을 반환 - 동사 ‘ran’은
pos에v를 함께 입력해주어야 원형인 ‘run’을 반환
영화 리뷰 데이터 전처리 #
python
file = open('moviereview.txt', 'r', encoding='utf-8')
lines = file.readlines()
sentence = lines[1]
tokens = nltk.word_tokenize(sentence)
lemmas = []
for token in tokens:
if token.lower() not in stop_words:
lemmas.append(lemmatizer.lemmatize(token))