[AI SCHOOL 5기] 텍스트 분석 실습 - 텍스트 분석
Scikit-learn Library #
- Traditional Machine Learning (vs DL, 인공신경을 썼는지의 여부)
python
from sklearn import datasets, linear_model, model_selection, metrics
data_total = datasets.load_boston()
x = data_total.data
y = data_total.target
train_x, test_x, train_y, test_y =
model_selection.train_test_split(x, y, test_size=0.3)
# 학습 전의 모델 생성
model = linear_model.LinearRegression()
# 모델에 학습 데이터를 넣으면서 학습 진행
model.fit(train_x, train_y)
# 모델에게 새로운 데이터를 주면서 예측 요구
predictions = model.predict(test_x)
# 예측 결과를 바탕으로 성능 점수 확인
metrics.mean_squared_error(predictions, test_y)- 실습에서 사용할 패키지
python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarityVectorizer #
python
corpus = [doc1, doc2, doc3]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus).todense()
# vertorizer.fit(corpus)
# X = vectorizer.trasnform(corpus)- Vectorizer는 리스트로 묶인 다수의 데이터에 대한 벡터 생성
fit_transform()은 기본적으로 메모리를 차지하는 ‘0’이라는 값들을 제외하고
좌표에 대한 값의 형태로 표시.todense(): ‘0’이라는 값들을 포함하여 행렬의 형태로 표시X.shape: Vectorizer의 모양 확인 (row, column)CountVectorizer(): 단어의 출연 횟수만으로 벡터 생성
Print Output #
python
[[0.0071001 0.00332632 0. ... 0. 0.00166316 0. ]
[0.00889703 0. 0.00138938 ... 0.00138938 0. 0.00138938]]Pandas Output #

3. Cosine Similarity #
python
cosine_similarity(X[0], X[1])[하나의 행 vs 전체 행] 구도로 표시 #
python
similarity = cosine_similarity(X[0], X)
# 위에서부터 순서대로 보기 위해 전치 행렬(Transpose)로 표시
pd.DataFrame(similarity.T)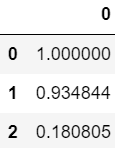
[각 행 vs 전체 행] 구도로 표시 #
python
similarity = cosine_similarity(X, X)
result = pd.DataFrame(similarity)
result.columns = ['Shawshank', 'Godfather', 'Inception']
result.index = ['Shawshank', 'Godfather', 'Inception']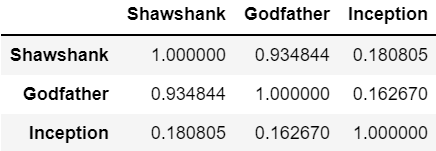
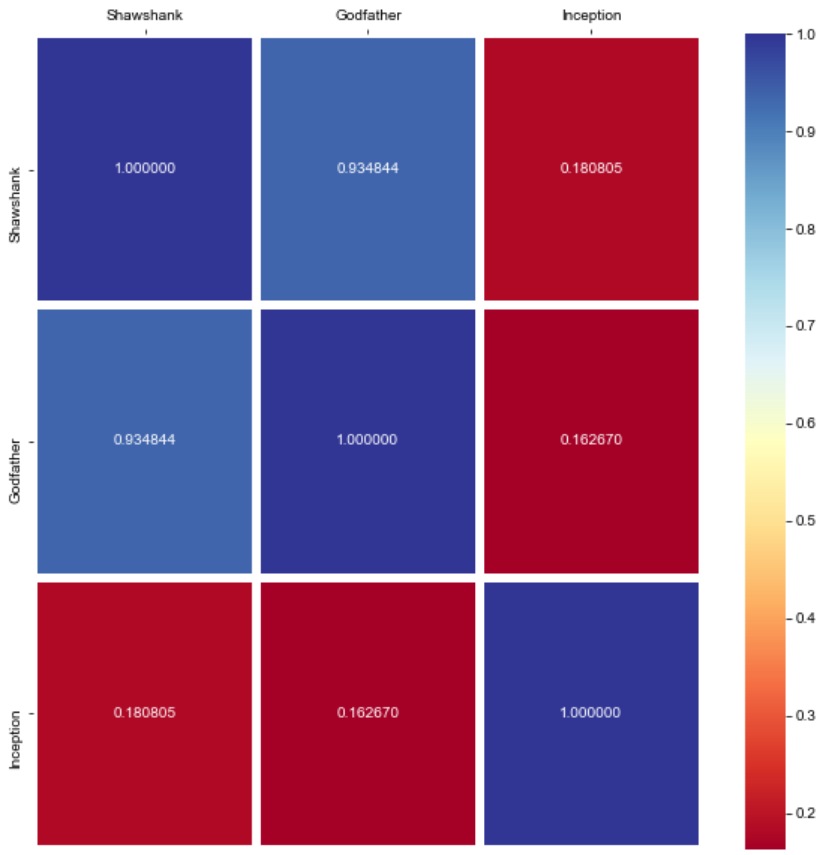
유사도 행렬 시각화 #
python
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
sns.heatmap(result, annot=True, fmt='f', linewidths=5, cmap='RdYlBu')
sns.set(font_scale=1.5)
plt.tick_params(top=True, bottom=False, labeltop=True, labelbottom=False)
plt.show()