[AI SCHOOL 5기] 통계분석 실습 - 빈도 분석 & 기술통계량 분석
Chart #
Pie Chart #
python
df['column'].value_counts().plot(kind = 'pie')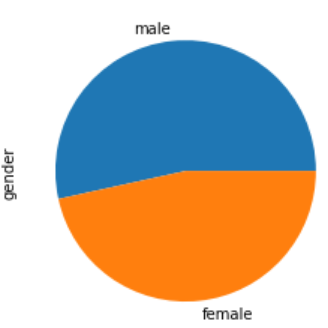
Bar Chart #
python
df['column'].value_counts().plot(kind = 'bar')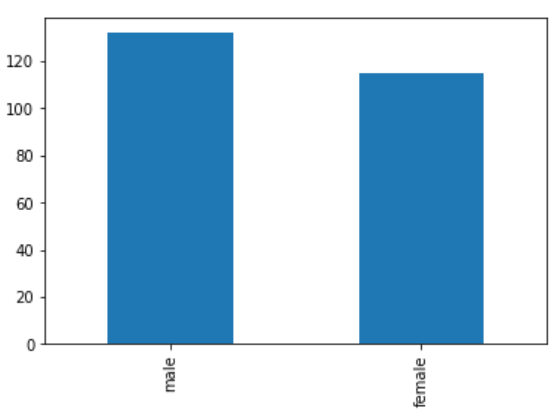
Descriptive Statistics #
df['column'].max(): 최댓값 (행방향 기준:axis=1)df['column'].min(): 최솟값df['column'].sum(): 합계df['column'].mean(): 평균df['column'].variance(): 분산df['column'].std(): 표준편차df['column'].describe(): 기술통계량
분포의 왜도와 첨도 #
df['column'].hist(): 히스토그램

df['column'].skew(): 왜도 (분포가 좌우로 치우쳐진 정도)- 왜도(Skewness): 0에 가까울수록 정규분포 (절대값 기준 3 미초과)
우측으로 치우치면 음(negative)의 왜도, 좌측으로 치우치면 양(positive)의 왜도 df['column'].kurtosis(): 첨도 (분포가 뾰족한 정도)- 첨도(Kurtosis): 1에 가까울수록 정규분포 (절대값 기준 8 또는 10 미초과)
- 왜도가 0, 정도가 1일 때 완전한 정규분포로 가정
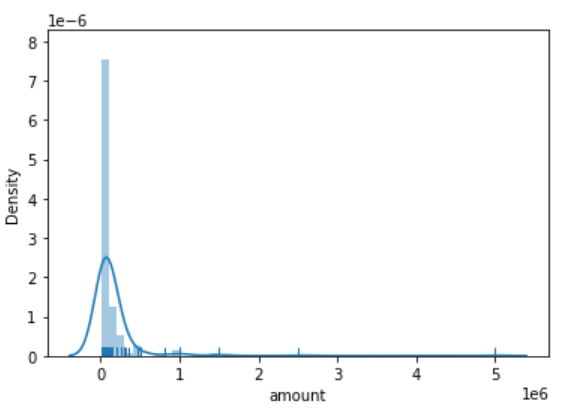
sns.distplot(df['column'], rug=True): distribution plotrug: 막대 그래프를 표시할지 여부
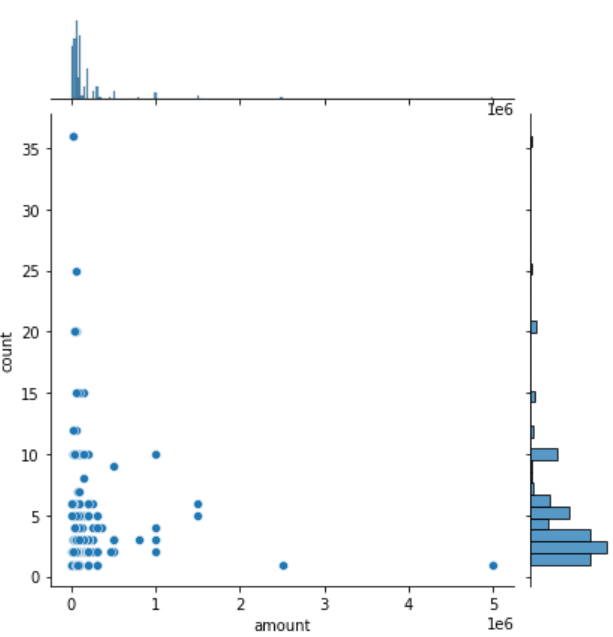
sns.jointplot(x='column1', y='column2', data=df): 산점도와 히스토그램 한번에 표시
sns.jointplot(..., kind="kde"): 밀집된 분포 곡선을 표시
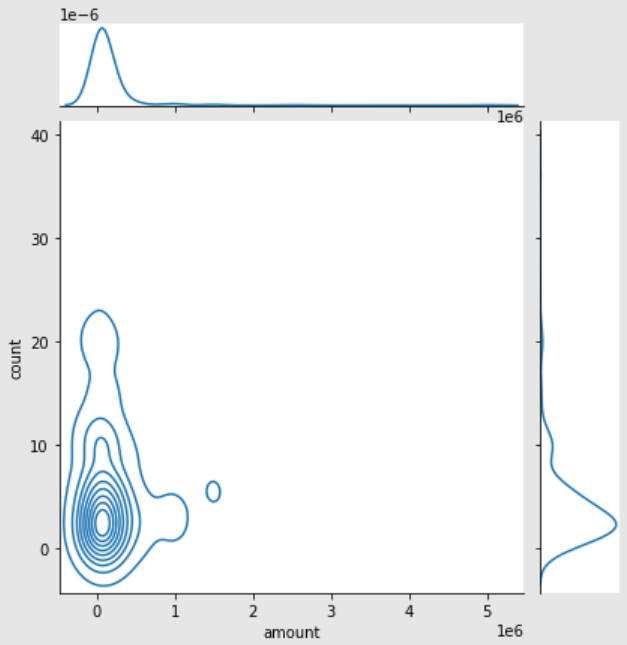
Outlier 탐지 및 제거 #
df.boxplot(column='column'): 데이터 전체에 걸쳐서 분포 밀집도를 표시
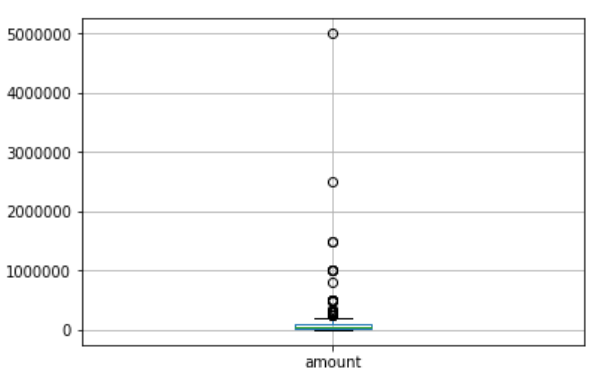
IQR 활용 #
- IQR(Inter-Quantile Range): 바닥부터 75% 지점의 값 - 바닥부터 25% 지점의 값
- 상한치: 바닥부터 75% 지점의 값 + IQR의 1.5배
- 하한치: 바닥부터 25% 지점의 값 - IQR의 1.5배
- 상한/하한치를 넘으면 Outlier로 판단
python
Q1 = df['column'].quantile(0.25)
Q3 = df['column'].quantile(0.75)
IQR = Q3 - Q1
df_IQR = df[ (df['column'] < Q3 + IQR * 1.5) & (df['column'] > Q1 - IQR * 1.5) ]
df_IQR.boxplot(column='column')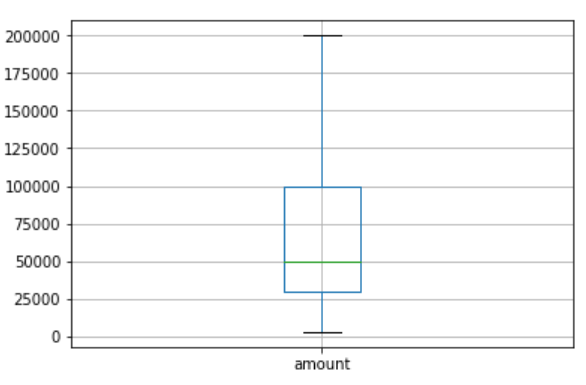
Outlier 제거 전후 분포 비교 #
Histogram #
| Before | After |
|---|---|
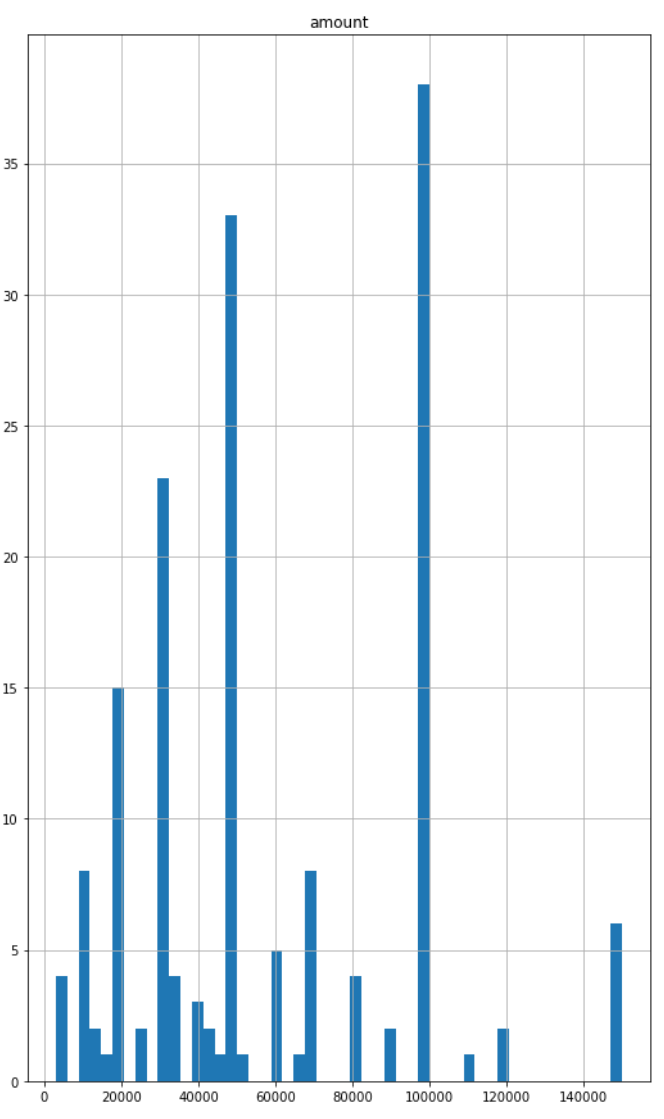 | 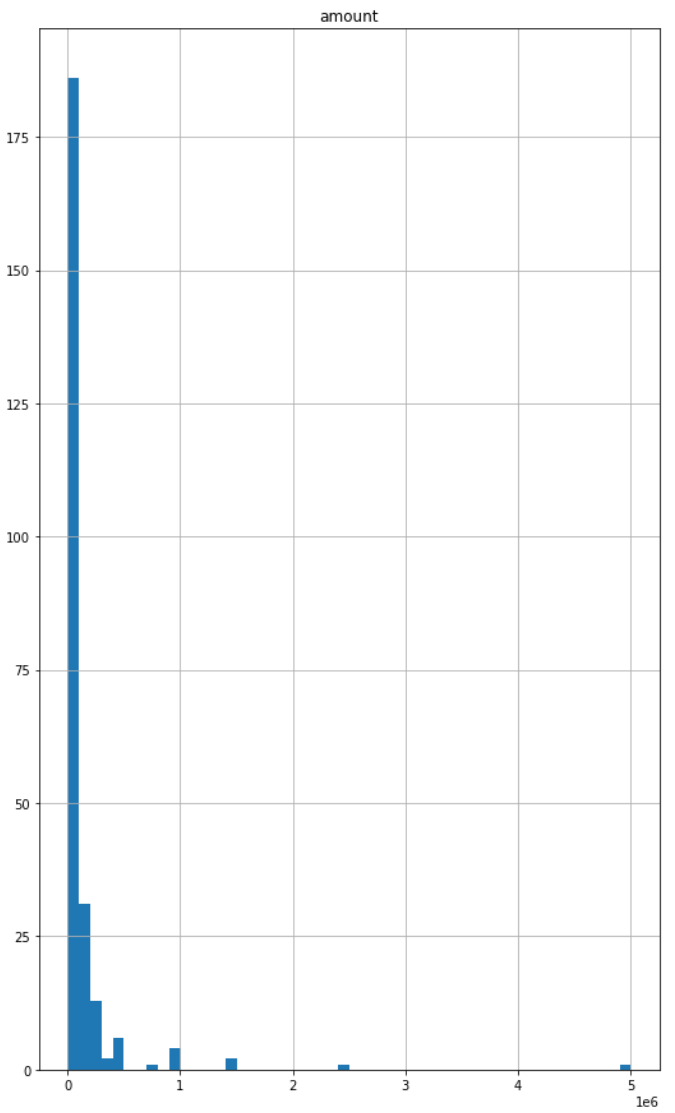 |
Joint-Plot #
| Before | After |
|---|---|
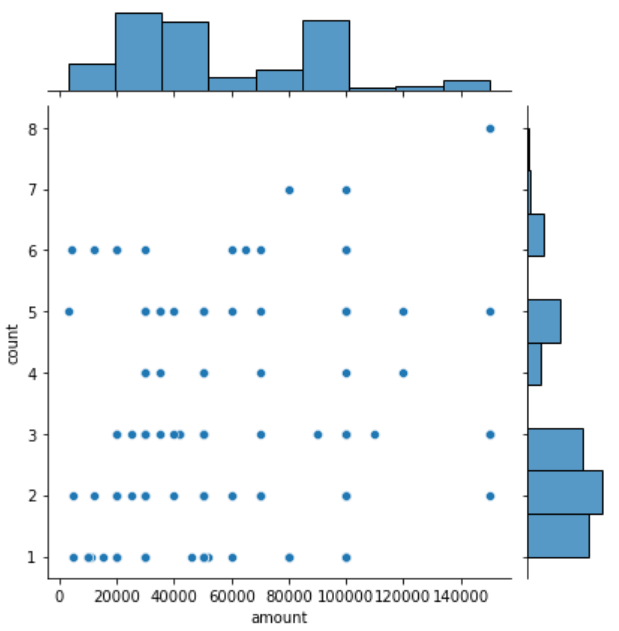 | 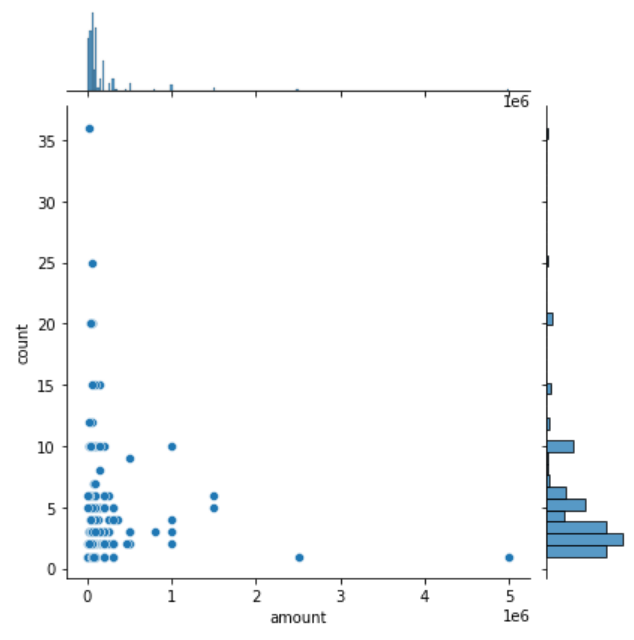 |
Log 함수를 활용한 데이터 스케일링 #
- 왜도 혹은 첨도가 너무 큰 경우, Log 함수를 적용해 왜도/첨도를 낮춰주는 전처리를 적용
processed_df['log_column'] = np.log(processed_df['column'])
| Before | After |
|---|---|
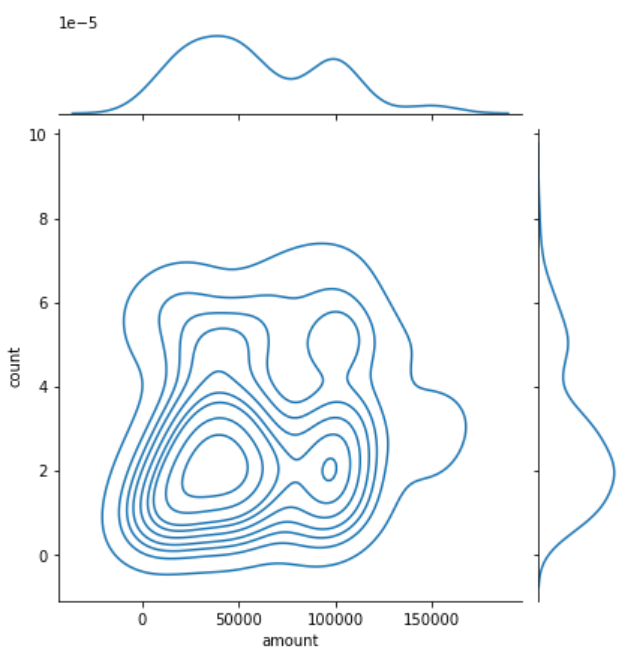 |  |